15場小組賽后,世界杯成了中國AI最誠實的考場
一張世界杯預測排行榜,正在變得比很多大模型評測基準更容易被公眾理解。
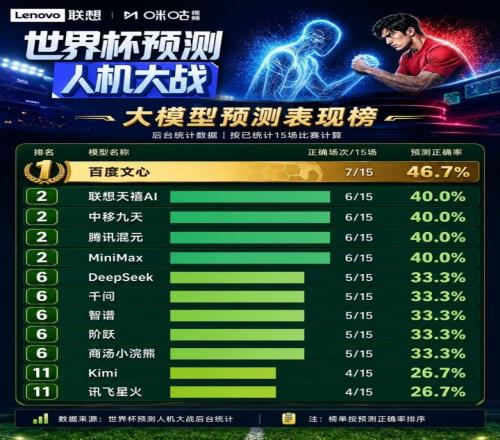
咪咕視頻與聯想集團聯合發起的“世界杯預測人機大戰”進行到第15場,12大AI模型的階段成績已經浮出水面:百度文心7場命中,勝率46.7%,暫列第一;聯想天禧AI、中移九天、騰訊混元、MiniMax均為6場命中,勝率40.0%,處于領先梯隊;
DeepSeek、通義千問、智譜、階躍星辰、商湯小浣熊均為5場命中,勝率33.3%;Kimi和訊飛星火均為4場命中,勝率26.7%。
這組數據本身并不復雜。真正值得關注的是,它把一個更大的問題推到了臺前:當大模型走出實驗室評測,進入一個有真實結果、有公開對照、有持續驗證的公共場景時,各家模型的表現會呈現出怎樣的差異?
世界杯正在給出一個足夠誠實的答案。
各家都在預測,但只有同一張答卷才能比較
世界杯開賽前一周,中國AI行業圍繞世界杯的營銷戰已經打響。
Kimi在世界杯前下場。6月8日,月之暗面宣布調度300個子Agent組成“Agent集群”,從戰術、球員、傷病、賽程、輿情、天氣、心理、賠率等多個維度,對104場比賽逐場做賽前預測和賽后復盤,并發布了系統性的預測報告。配合“萬億Token”瓜分活動,Kimi也給出了一個有強傳播力的自我提示:“我們的預測很可能是錯的。”

千問緊隨其后。阿里在6月11日上線“足球預測AI助手”,面向用戶開放,強調引入球隊、球員之外的環境變量,包括美加墨三國的地貌、海拔、濕度和比賽日天氣數據。同時,“千問球場計劃”把競猜積分與鄉村學校足球場捐建掛鉤,把世界杯預測與公益傳播結合起來。
DeepSeek、智譜、百度文心、訊飛星火、商湯等模型,也都以不同方式進入世界杯預測場景。整個行業都意識到了同一件事:48支球隊、104場比賽、39天賽程、全球關注,這幾乎是2026年最天然的AI公共展示舞臺。
但問題也隨之出現:各家各做各的,外界很難比較。
一個用戶想知道DeepSeek和Kimi誰猜得更準,需要分別去不同平臺查預測,再手動對照賽果。放到104場比賽的體量里,這件事幾乎不現實。更重要的是,各家預測的發布時間、呈現格式、分析維度和復盤口徑并不統一,缺少同一張答卷,也就很難形成真正的橫向比較。

事實上,早在Kimi、千問單個模型下場之前,聯想集團與咪咕已經攢起了全球首個多AI同臺進行世界杯預測的局。
這場由咪咕與聯想天禧AI聯合發起的世界杯預測人機大戰”中,DeepSeek、Kimi、千問、百度文心、騰訊混元、智譜、MiniMax、階躍星辰、訊飛星火、商湯小浣熊、中移九天等國內主流大模型,與天禧AI自身放在同一張頁面上,對每場比賽給出統一格式的勝平負和比分預測。所有預測賽前同步展示,賽后即時驗證,全程公開記錄。
這不是技術上最復雜的方案,卻可能是傳播上最有效的方案:它讓“AI誰更懂球”這件事,從各說各話,變成了同場考試。
技術方案越復雜,就一定越準嗎?
15場數據已經足夠讓人看到一些反直覺的結果。
Kimi拿出了行業里最重的世界杯預測方案之一:300個Agent集群并行推演,覆蓋戰術、賠率、心理、天氣等多個分析維度。從技術復雜度和資源投入看,這幾乎是本屆世界杯AI預測賽道中最“豪華”的配置之一。
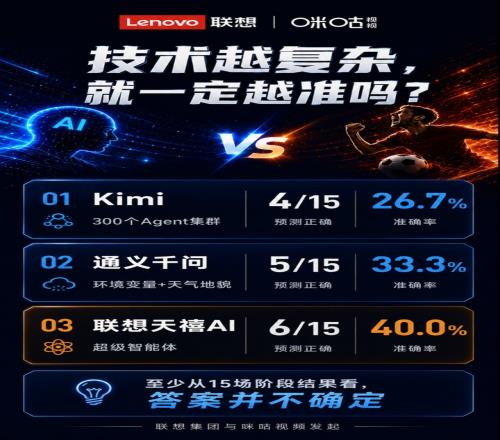
但15場過后,Kimi階段成績為4場命中,勝率26.7%。
通義千問引入了地貌、天氣等環境數據。這些維度理論上能補足傳統足球分析中容易被忽略的變量。但15場過后,通義千問5場命中,勝率33.3%。
反觀聯想天禧AI,它沒有把傳播重點放在“調用了多少Agent”或“納入多少維度”上,而是以超級智能體的方式給出自己的判斷,同時把其他11家模型的判斷一起放進同一個可驗證場景。15場過后,聯想天禧AI6場命中,勝率40.0%,位于領先梯隊,與榜首只差一場。
這組對比并不能簡單推出“復雜架構無效”的結論。15場樣本仍然有限,足球預測本身也高度依賴偶然性。但它至少提出了一個值得討論的問題:在足球預測這樣強不確定性的場景里,更多Agent、更復雜維度,是否一定能轉化為更高命中率?
至少從階段結果看,答案并不確定。
這也是世界杯作為AI驗證場景的獨特之處。它不關心模型講了多少推理鏈條,也不關心預測報告寫了多少頁。最終,只有一個問題:終場比分是否站在你這一邊。

平局盲區:12個模型共同遇到的難題
15場比賽,已經出現6場平局,平局率達到40%。
這一比例顯著高于世界杯小組賽常見的平局水平,也對AI陣營形成了系統性考驗。在6場平局中,12大AI合計只有4次命中賽果:騰訊混元、Kimi、訊飛星火命中加拿大1-1波黑,階躍星辰命中比利時1-1埃及。
換句話說,AI在平局場景中的命中率,明顯低于它們在非平局比賽中的表現。

強弱分明的比賽里,AI表現并不差。例如德國7-1庫拉索、瑞典5-1突尼斯等比賽,多數模型甚至能夠全部命中勝負方向。但一旦比賽進入平局、低比分、門將發揮、臨場失誤和節奏拉扯共同作用的場景,模型就很容易失準。
這并非某一家模型的個體問題,而是多個模型共同暴露出的難題。
為什么大模型不擅長預測平局?一個可能的解釋是,足球語料天然偏向“勝負敘事”。賽前分析、賽后報道、球迷討論、歷史戰績數據庫,往往圍繞“誰贏了”“誰更強”“誰爆冷”展開。平局在真實比賽中并不罕見,卻很少成為敘事中心。
另一個可能的解釋,是推理框架的慣性。當模型被要求預測一場比賽時,它往往會從排名、身價、陣容、歷史交鋒等維度出發,最終回答“哪一方更有優勢”。這更接近一個排序問題。
但平局不是簡單的排序結果。它意味著兩支球隊在90分鐘里的機會、失誤、節奏、心理和偶然性,最終抵消了紙面差距。這要求模型不僅判斷誰更強,還要判斷優勢能否轉化為勝利。后者是更復雜的概率校準問題。
這正是“世界杯預測人機大戰”作為公開實驗的價值所在:它不只展示AI何時正確,也暴露AI在哪些場景下最容易失準,而且這種暴露是持續的、可追蹤的、不可回避的。
AI需要一個世界杯
過去幾年,中國AI行業的能力驗證主要依賴三類方式:基準測試、產品數據和事件營銷。
基準測試可以給出標準化分數,但離真實使用場景較遠;產品數據能體現用戶規模和調用量,卻難以橫向比較;事件營銷容易形成傳播爆點,但往往只有一次性結論。
世界杯提供了一種完全不同的驗證框架:真實場景、統一題面、持續驗證、公開結果、全民參與。
104場比賽,每一場都是一道新題;每一道題都有確定答案;所有參與者面對同一張試卷;每一次判斷都會在終場哨響后被檢驗。這種場景對AI行業來說極其稀缺。
這也是聯想集團選擇在世界杯上發起“人機大戰”的深層邏輯。
“世界杯預測人機大戰”面向消費者、球迷和普通公眾。很多人可能并不關心模型參數、推理成本和評測分數,但他們一定能理解“這場球誰會贏”“AI猜得準不準”。
讓12大AI在世界杯賽場上接受公開驗證,讓AI的能力和局限被更廣泛的人看到、討論、參與,這件事的價值正在隨著賽事推進不斷放大。
Kimi的預測報告很專業,通義千問的環境數據很新穎,百度文心暫時領跑,聯想天禧AI處于領先梯隊。它們各有特點。但這些差異,只有在同一張答卷上,才真正能被看見。
當很多AI公司都在各自舞臺上展示能力時,聯想做了一件更接近“基礎設施”的事:搭建一個共同舞臺,讓賽果來當裁判。
89場比賽還在后面
15場,只完成了全部賽程的一小部分。小組賽還有大量比賽,淘汰賽也將在后續展開。比賽形態會從“強弱對話”,逐漸轉向“強強對決”和“生死戰”。這些新場景中,AI的表現是否會發生變化?平局率是否會回歸常見水平?當前排名是否會被改寫?
現在下最終結論還為時過早。
但15場數據已經足夠說明一件事:AI行業需要的不只是更大的參數、更多的Agent和更復雜的數據維度,也需要一個真實、持續、公開的驗證場景,讓能力被看見,也讓局限被看見。
世界杯恰好是這樣一個場景。
而聯想集團聯合咪咕,搭建了這個讓12大AI同場接受檢驗的平臺。
這可能是“世界杯預測人機大戰”進行到15場后,給中國AI行業留下的最重要啟示。
打開咪咕視頻APP搜索人機大戰,登錄聯想天禧AI相關入口,即可參與世界杯預測人機大戰。6月24日起,咪咕視頻與聯想集團聯合出品的《人機大戰:誰是世界杯預言家》將在咪咕視頻正式開播,敬請期待。
足球免費觀看_足球高清在線
 回到頂部
回到頂部